
初级
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
第一步:将内容封装到某处

self 是一个形式参数,当执行 obj1 = Foo('wupeiqi', 18 ) 时,self 等于 obj1
当执行 obj2 = Foo('alex', 78 ) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。

第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
obj1 = Foo('wupeiqi', 18)
print obj1.name # 直接调用obj1对象的name属性
print obj1.age # 直接调用obj1对象的age属性
obj2 = Foo('alex', 73)
print obj2.name # 直接调用obj2对象的name属性
print obj2.age # 直接调用obj2对象的age属性
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print self.name
print self.age
obj1 = Foo('wupeiqi', 18)
obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 wupeiqi ;self.age 是 18
obj2 = Foo('alex', 73)
obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 alex ; self.age 是 78
综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
二、继承
继承,面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。
例如:
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别为猫和狗创建一个类,那么就需要为 猫 和 狗 实现他们所有的功能
上述代码不难看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现:
动物:吃、喝、拉、撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
所以,对于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
注:除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。

那么问题又来了,多继承呢?
- 是否可以继承多个类
- 如果继承的多个类每个类中都定了相同的函数,那么那一个会被使用呢?
1、Python的类可以继承多个类,Java和C#中则只能继承一个类
2、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先

- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。


经典类多继承
class D:
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> D --> C
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
新式类多继承
class D(object):
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> C --> D
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
区别主要在Python 2中显著,因为Python 3中所有的类默认都是新式类,即它们自动继承自object。
-
经典类(Python 2特有)
经典类不显式地继承自object。
它们使用旧式的类机制,这在一些方面与新式类有所不同,特别是在方法解析顺序(Method Resolution Order, MRO)和多态性方面。
经典类在Python 2中是默认的类类型,除非显式地继承自object。 -
新式类(Python 2和Python 3)
新式类显式地继承自object(在Python 3中,这是隐式的,因为所有类默认都继承自object)。
它们引入了许多新特性,包括super()函数、属性(properties)、__slots__类变量、__getattribute__和__setattr__等高级方法的改进实现。
新式类采用C3线性化算法来解析方法继承顺序,这有助于更精确地控制方法的调用顺序,减少了方法覆盖带来的问题。
新式类支持元类(metaclass),这是一个强大的特性,允许你控制类的创建过程。 -
主要区别
继承:经典类不自动继承自object,而新式类则自动或显式地继承自object。
MRO:新式类使用C3线性化算法来确定方法解析顺序,而经典类使用深度优先搜索(DFS)算法。
特性:新式类支持super()函数、属性、slots、元类等高级特性,而经典类则不支持这些。
默认行为:在Python 3中,所有类默认都是新式类,而Python 2中需要显式继承object才能成为新式类。
三、多态
Pyhon不支持Java和C#这一类强类型语言中多态的写法,但是原生多态,其Python崇尚“鸭子类型”。
# Python伪代码实现Java或C#的多态
class F1:
pass
class S1(F1):
def show(self):
print 'S1.show'
class S2(F1):
def show(self):
print 'S2.show'
# 由于在Java或C#中定义函数参数时,必须指定参数的类型
# 为了让Func函数既可以执行S1对象的show方法,又可以执行S2对象的show方法,所以,定义了一个S1和S2类的父类
# 而实际传入的参数是:S1对象和S2对象
def Func(F1 obj):
"""Func函数需要接收一个F1类型或者F1子类的类型"""
print obj.show()
s1_obj = S1()
Func(s1_obj) # 在Func函数中传入S1类的对象 s1_obj,执行 S1 的show方法,结果:S1.show
s2_obj = S2()
Func(s2_obj) # 在Func函数中传入Ss类的对象 ss_obj,执行 Ss 的show方法,结果:S2.show
Python “鸭子类型” Dynamic Typing
在Python中,如果一个对象可以执行我们期望的操作(比如有show方法),
那么我们就不需要关心它具体的类型是什么。
只要它“走起来像鸭子,叫起来也像鸭子,那么我们就可以把它当作鸭子”。
# Python “鸭子类型” Dynamic Typing
class F1:
pass
class S1(F1):
def show(self):
print 'S1.show'
class S2(F1):
def show(self):
print 'S2.show'
def Func(obj):
print obj.show()
s1_obj = S1()
Func(s1_obj)
s2_obj = S2()
Func(s2_obj)
总结
以上就是本节对于面向对象初级知识的介绍,总结如下:
- 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用
- 类 是一个模板,模板中包装了多个“函数”供使用
- 对象,根据模板创建的实例(即:对象),实例用于调用被包装在类中的函数
- 面向对象三大特性:封装、继承和多态
问答专区
问题一:什么样的代码才是面向对象?
答:从简单来说,如果程序中的所有功能都是用 类 和 对象 来实现,那么就是面向对象编程了。
问题二:函数式编程 和 面向对象 如何选择?分别在什么情况下使用?
答:须知:对于 C# 和 Java 程序员来说不存在这个问题,因为该两门语言只支持面向对象编程(不支持函数式编程)。而对于 Python 和 PHP 等语言却同时支持两种编程方式,且函数式编程能完成的操作,面向对象都可以实现;而面向对象的能完成的操作,函数式编程不行(函数式编程无法实现面向对象的封装功能)。
所以,一般在Python开发中,全部使用面向对象 或 面向对象和函数式混合使用
面向对象的应用场景:
-
多函数需使用共同的值,如:数据库的增、删、改、查操作都需要连接数据库字符串、主机名、用户名和密码
# Demo class SqlHelper: def __init__(self, host, user, pwd): self.host = host self.user = user self.pwd = pwd def 增(self): # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 # do something # 关闭数据库连接 def 删(self): # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 # do something # 关闭数据库连接 def 改(self): # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 # do something # 关闭数据库连接 def 查(self): # 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接 # do something # 关闭数据库连接# do something -
需要创建多个事物,每个事物属性个数相同,但是值的需求
如:张三、李四、杨五,他们都有姓名、年龄、血型,但其都是不相同。即:属性个数相同,但值不相同
class Person: def __init__(self, name ,age ,blood_type): self.name = name self.age = age self.blood_type = blood_type def detail(self): temp = "i am %s, age %s , blood type %s " % (self.name, self.age, self.blood_type) print temp zhangsan = Person('张三', 18, 'A') lisi = Person('李四', 73, 'AB') yangwu = Person('杨五', 84, 'A') Demo
问题三:类和对象在内存中是如何保存?
答:类以及类中的方法在内存中只有一份,而根据类创建的每一个对象都在内存中需要存一份,大致如下图:

如上图所示,根据类创建对象时,对象中除了封装 name 和 age 的值之外,还会保存一个类对象指针,该值指向当前对象的类。
当通过 obj1 执行 【方法一】 时,过程如下:
- 根据当前对象中的 类对象指针 找到类中的方法
- 将对象 obj1 当作参数传给 方法的第一个参数 self
进阶
类的成员
类的成员可以分为三大类:字段、方法和属性
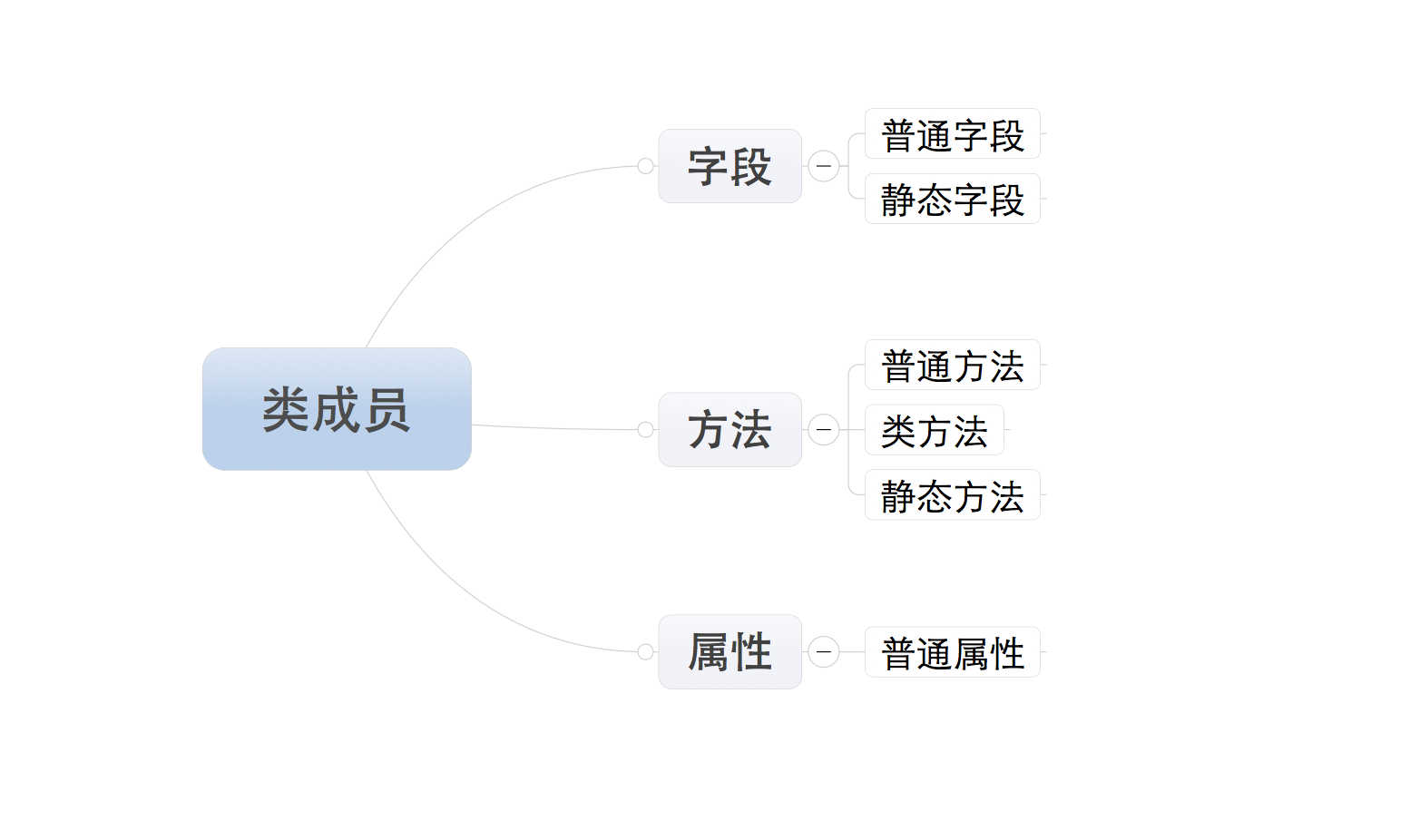
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
一、字段
字段包括:普通字段和静态字段,他们在定义和使用中有所区别,而最本质的区别是内存中保存的位置不同,
- 普通字段属于对象
- 静态字段属于类
# 字段的定义和使用
class Province:
# 静态字段
country = '中国'
def __init__(self, name):
# 普通字段
self.name = name
# 直接访问普通字段
obj = Province('河北省')
print obj.name
# 直接访问静态字段
Province.country
由上述代码可以看出【普通字段需要通过对象来访问】【静态字段通过类访问】,在使用上可以看出普通字段和静态字段的归属是不同的。其在内容的存储方式类似如下图:

由上图可是:
- 静态字段在内存中只保存一份
- 普通字段在每个对象中都要保存一份
应用场景: 通过类创建对象时,如果每个对象都具有相同的字段,那么就使用静态字段
二、方法
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
-
普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
-
类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
cls参数是一个对类本身的引用 -
静态方法:由类调用;无默认参数;
# 方法的定义和使用
class Foo:
def __init__(self, name):
self.name = name
def ord_func(self):
""" 定义普通方法,至少有一个self参数 """
# print self.name
print '普通方法'
@classmethod
def class_func(cls):
""" 定义类方法,至少有一个cls参数 """
print '类方法'
@staticmethod
def static_func():
""" 定义静态方法 ,无默认参数"""
print '静态方法'
# 调用普通方法
f = Foo()
f.ord_func()
# 调用类方法
Foo.class_func()
# 调用静态方法
Foo.static_func()

**相同点:**对于所有的方法而言,均属于类(非对象)中,所以,在内存中也只保存一份。
**不同点:**方法调用者不同、调用方法时自动传入的参数不同。
三、属性
如果你已经了解Python类中的方法,那么属性就非常简单了,因为Python中的属性其实是普通方法的变种。
对于属性,有以下三个知识点:
- 属性的基本使用
- 属性的两种定义方式
1、属性的基本使用
# 属性的定义和使用
# ############### 定义 ###############
class Foo:
def func(self):
pass
# 定义属性
@property
def prop(self):
pass
# ############### 调用 ###############
foo_obj = Foo()
foo_obj.func()
foo_obj.prop #调用属性
由属性的定义和调用要注意一下几点:
- 定义时,在普通方法的基础上添加 @property 装饰器;
- 定义时,属性仅有一个self参数
- 调用时,无需括号
方法:foo_obj.func()
属性:foo_obj.prop
注意:属性存在意义是:访问属性时可以制造出和访问字段完全相同的假象
属性由方法变种而来,如果Python中没有属性,方法完全可以代替其功能。
实例:对于主机列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据(即:limit m,n),这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
# ############### 定义 ###############
class Pager:
def __init__(self, current_page):
# 用户当前请求的页码(第一页、第二页...)
self.current_page = current_page
# 每页默认显示10条数据
self.per_items = 10
@property
def start(self):
val = (self.current_page - 1) * self.per_items
return val
@property
def end(self):
val = self.current_page * self.per_items
return val
# ############### 调用 ###############
p = Pager(1)
p.start 就是起始值,即:m
p.end 就是结束值,即:n
从上述可见,Python的属性的功能是:属性内部进行一系列的逻辑计算,最终将计算结果返回。
2、属性的两种定义方式
属性的定义有两种方式:
- 装饰器 即:在方法上应用装饰器
- 静态字段 即:在类中定义值为property对象的静态字段
装饰器方式:在类的普通方法上应用@property装饰器
我们知道Python中的类有经典类和新式类,新式类的属性比经典类的属性丰富。( 如果类继object,那么该类是新式类 )
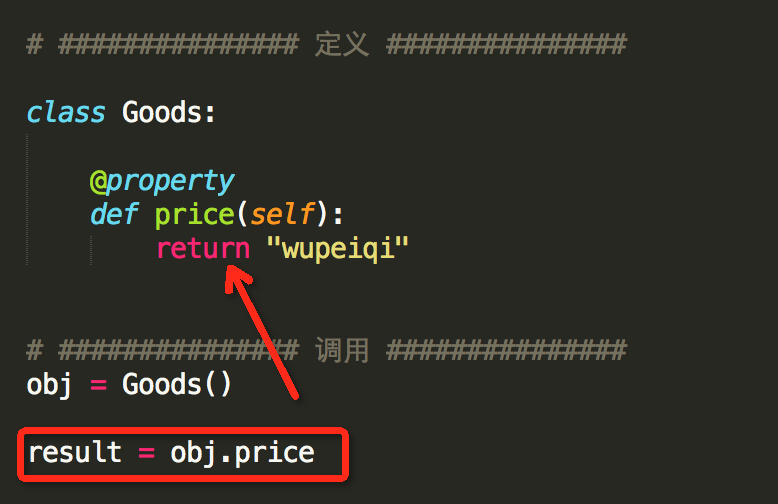
经典类,具有一种@property装饰器(如上一步实例)# ############### 定义 ############### class Goods: @property def price(self): return "wupeiqi" # ############### 调用 ############### obj = Goods() result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值新式类,具有三种@property装饰器
# ############### 定义 ############### class Goods(object): @property def price(self): print '@property' @price.setter def price(self, value): print '@price.setter' @price.deleter def price(self): print '@price.deleter' # ############### 调用 ############### obj = Goods() obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值 obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数 del obj.price # 自动执行 @price.deleter 修饰的 price 方法注:经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法由于新式类中具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
# 实例 class Goods(object): def __init__(self): # 原价 self.original_price = 100 # 折扣 self.discount = 0.8 @property def price(self): # 实际价格 = 原价 * 折扣 new_price = self.original_price * self.discount return new_price @price.setter def price(self, value): self.original_price = value @price.deltter def price(self, value): del self.original_price obj = Goods() obj.price # 获取商品价格 obj.price = 200 # 修改商品原价 del obj.price # 删除商品原价
静态字段方式,创建值为property对象的静态字段
当使用静态字段的方式创建属性时,经典类和新式类无区别
class Foo: def get_bar(self): return 'wupeiqi' BAR = property(get_bar) obj = Foo() reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值 print reusltproperty的构造方法中有个四个参数
- 第一个参数是方法名,调用
对象.属性时自动触发执行方法- 第二个参数是方法名,调用
对象.属性 = XXX时自动触发执行方法- 第三个参数是方法名,调用
del 对象.属性时自动触发执行方法- 第四个参数是字符串,调用
对象.属性.__doc__,此参数是该属性的描述信息class Foo: def get_bar(self): return 'wupeiqi' # *必须两个参数 def set_bar(self, value): return return 'set value' + value def del_bar(self): return 'wupeiqi' BAR = property(get_bar, set_bar, del_bar, 'description...') obj = Foo() obj.BAR # 自动调用第一个参数中定义的方法:get_bar obj.BAR = "alex" # 自动调用第二个参数中定义的方法:set_bar方法,并将“alex”当作参数传入 del Foo.BAR # 自动调用第三个参数中定义的方法:del_bar方法 obj.BAE.__doc__ # 自动获取第四个参数中设置的值:description...由于静态字段方式创建属性具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
# 实例 class Goods(object): def __init__(self): # 原价 self.original_price = 100 # 折扣 self.discount = 0.8 def get_price(self): # 实际价格 = 原价 * 折扣 new_price = self.original_price * self.discount return new_price def set_price(self, value): self.original_price = value def del_price(self, value): del self.original_price PRICE = property(get_price, set_price, del_price, '价格属性描述...') obj = Goods() obj.PRICE # 获取商品价格 obj.PRICE = 200 # 修改商品原价 del obj.PRICE # 删除商品原价注意:Python WEB框架 Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性
# Django源码 class WSGIRequest(http.HttpRequest): def __init__(self, environ): script_name = get_script_name(environ) path_info = get_path_info(environ) if not path_info: # Sometimes PATH_INFO exists, but is empty (e.g. accessing # the SCRIPT_NAME URL without a trailing slash). We really need to # operate as if they'd requested '/'. Not amazingly nice to force # the path like this, but should be harmless. path_info = '/' self.environ = environ self.path_info = path_info self.path = '%s/%s' % (script_name.rstrip('/'), path_info.lstrip('/')) self.META = environ self.META['PATH_INFO'] = path_info self.META['SCRIPT_NAME'] = script_name self.method = environ['REQUEST_METHOD'].upper() _, content_params = cgi.parse_header(environ.get('CONTENT_TYPE', '')) if 'charset' in content_params: try: codecs.lookup(content_params['charset']) except LookupError: pass else: self.encoding = content_params['charset'] self._post_parse_error = False try: content_length = int(environ.get('CONTENT_LENGTH')) except (ValueError, TypeError): content_length = 0 self._stream = LimitedStream(self.environ['wsgi.input'], content_length) self._read_started = False self.resolver_match = None def _get_scheme(self): return self.environ.get('wsgi.url_scheme') def _get_request(self): warnings.warn('`request.REQUEST` is deprecated, use `request.GET` or ' '`request.POST` instead.', RemovedInDjango19Warning, 2) if not hasattr(self, '_request'): self._request = datastructures.MergeDict(self.POST, self.GET) return self._request @cached_property def GET(self): # The WSGI spec says 'QUERY_STRING' may be absent. raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '') return http.QueryDict(raw_query_string, encoding=self._encoding) # ############### 看这里看这里 ############### def _get_post(self): if not hasattr(self, '_post'): self._load_post_and_files() return self._post # ############### 看这里看这里 ############### def _set_post(self, post): self._post = post @cached_property def COOKIES(self): raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '') return http.parse_cookie(raw_cookie) def _get_files(self): if not hasattr(self, '_files'): self._load_post_and_files() return self._files # ############### 看这里看这里 ############### POST = property(_get_post, _set_post) FILES = property(_get_files) REQUEST = property(_get_request)
所以,定义属性共有两种方式,分别是【装饰器】和【静态字段】,而【装饰器】方式针对经典类和新式类又有所不同。
类成员的修饰符
类的所有成员在上一步骤中已经做了详细的介绍,对于每一个类的成员而言都有两种形式:
- 公有成员,在任何地方都能访问
- 私有成员,只有在类的内部才能方法
私有成员和公有成员的定义不同:私有成员命名时,前两个字符是下划线。(特殊成员除外,例如:init、call、__dict__等)
class C:
def __init__(self):
self.name = '公有字段'
self.__foo = "私有字段"
私有成员和公有成员的访问限制不同:
静态字段
- 公有静态字段:类可以访问;类内部可以访问;派生类中可以访问
- 私有静态字段:仅类内部可以访问;
公有静态字段
class C:
name = "公有静态字段"
def func(self):
print C.name
class D(C):
def show(self):
print C.name
C.name # 类访问
obj = C()
obj.func() # 类内部可以访问
obj_son = D()
obj_son.show() # 派生类中可以访问
私有静态字段
class C:
__name = "公有静态字段"
def func(self):
print C.__name
class D(C):
def show(self):
print C.__name
C.__name # 类访问 ==> 错误
obj = C()
obj.func() # 类内部可以访问 ==> 正确
obj_son = D()
obj_son.show() # 派生类中可以访问 ==> 错误
普通字段
- 公有普通字段:对象可以访问;类内部可以访问;派生类中可以访问
- 私有普通字段:仅类内部可以访问;
ps:如果想要强制访问私有字段,可以通过 【对象._类名__私有字段明 】访问(如:obj._C__foo),不建议强制访问私有成员。
公有字段
class C:
def __init__(self):
self.foo = "公有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.foo # 通过对象访问
obj.func() # 类内部访问
obj_son = D();
obj_son.show() # 派生类中访问
私有字段
class C:
def __init__(self):
self.__foo = "私有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.__foo # 通过对象访问 ==> 错误
obj.func() # 类内部访问 ==> 正确
obj_son = D();
obj_son.show() # 派生类中访问 ==> 错误
方法、属性的访问于上述方式相似,即:私有成员只能在类内部使用
ps:非要访问私有属性的话,可以通过 对象._类__属性名
类的特殊成员
上文介绍了Python的类成员以及成员修饰符,从而了解到类中有字段、方法和属性三大类成员,并且成员名前如果有两个下划线,则表示该成员是私有成员,私有成员只能由类内部调用。无论人或事物往往都有不按套路出牌的情况,Python的类成员也是如此,存在着一些具有特殊含义的成员,详情如下:
1. doc
表示类的描述信息
class Foo:
""" 描述类信息,这是用于看片的神奇 """
def func(self):
pass
print Foo.__doc__
#输出:类的描述信息
2. module 和 class
module 表示当前操作的对象在那个模块
class 表示当前操作的对象的类是什么
lib/aa.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class C:
def __init__(self):
self.name = 'wupeiqi'
index.py
from lib.aa import C
obj = C()
print obj.__module__ # 输出 lib.aa,即:输出模块
print obj.__class__ # 输出 lib.aa.C,即:输出类
3. init
构造方法,通过类创建对象时,自动触发执行。
class Foo:
def __init__(self, name):
self.name = name
self.age = 18
obj = Foo('wupeiqi') # 自动执行类中的 __init__ 方法
4. del
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
class Foo:
def __del__(self):
pass
5. call
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 call 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
class Foo:
def __init__(self):
pass
def __call__(self, *args, **kwargs):
print '__call__'
obj = Foo() # 执行 __init__
obj() # 执行 __call__
6. dict
类或对象中的所有成员
上文中我们知道:类的普通字段属于对象;类中的静态字段和方法等属于类,即:
class Province:
country = 'China'
def __init__(self, name, count):
self.name = name
self.count = count
def func(self, *args, **kwargs):
print 'func'
# 获取类的成员,即:静态字段、方法、
print Province.__dict__
# 输出:{'country': 'China', '__module__': '__main__', 'func': <function func at 0x10be30f50>, '__init__': <function __init__ at 0x10be30ed8>, '__doc__': None}
obj1 = Province('HeBei',10000)
print obj1.__dict__
# 获取 对象obj1 的成员
# 输出:{'count': 10000, 'name': 'HeBei'}
obj2 = Province('HeNan', 3888)
print obj2.__dict__
# 获取 对象obj1 的成员
# 输出:{'count': 3888, 'name': 'HeNan'}
7. str
如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值。
class Foo:
def __str__(self):
return 'wupeiqi'
obj = Foo()
print obj
# 输出:wupeiqi
8、getitem、setitem、delitem
用于索引操作,如字典。以上分别表示获取、设置、删除数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class Foo(object):
def __getitem__(self, key):
print '__getitem__',key
def __setitem__(self, key, value):
print '__setitem__',key,value
def __delitem__(self, key):
print '__delitem__',key
obj = Foo()
result = obj['k1'] # 自动触发执行 __getitem__
obj['k2'] = 'wupeiqi' # 自动触发执行 __setitem__
del obj['k1'] # 自动触发执行 __delitem__
9、getslice、setslice、delslice
该三个方法用于分片操作,如:列表
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class Foo(object):
def __getslice__(self, i, j):
print '__getslice__',i,j
def __setslice__(self, i, j, sequence):
print '__setslice__',i,j
def __delslice__(self, i, j):
print '__delslice__',i,j
obj = Foo()
obj[-1:1] # 自动触发执行 __getslice__
obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__
del obj[0:2] # 自动触发执行 __delslice__
10. iter
用于迭代器,之所以列表、字典、元组可以进行for循环,是因为类型内部定义了 iter
第一步
class Foo(object):
pass
obj = Foo()
for i in obj:
print i
# 报错:TypeError: 'Foo' object is not iterable
第二步
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class Foo(object):
def __iter__(self):
pass
obj = Foo()
for i in obj:
print i
# 报错:TypeError: iter() returned non-iterator of type 'NoneType'
第三步
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class Foo(object):
def __iter__(self):
pass
obj = Foo()
for i in obj:
print i
# 报错:TypeError: iter() returned non-iterator of type 'NoneType'
以上步骤可以看出,for循环迭代的其实是 iter([11,22,33,44]) ,所以执行流程可以变更为:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
obj = iter([11,22,33,44])
for i in obj:
print i
For循环语法内部
#!/usr/bin/env python
# -*- coding:utf-8 -*-
obj = iter([11,22,33,44])
while True:
val = obj.next()
print val
11. new 和 metaclass
阅读以下代码:
class Foo(object):
def __init__(self):
pass
obj = Foo() # obj是通过Foo类实例化的对象
上述代码中,obj 是通过 Foo 类实例化的对象,其实,不仅 obj 是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象。
如果按照一切事物都是对象的理论:obj对象是通过执行Foo类的构造方法创建,那么Foo类对象应该也是通过执行某个类的 构造方法 创建。
print type(obj) # 输出:<class '__main__.Foo'> 表示,obj 对象由Foo类创建
print type(Foo) # 输出:<type 'type'> 表示,Foo类对象由 type 类创建
所以,obj对象是Foo类的一个实例,Foo类对象是 type 类的一个实例,即:Foo类对象 是通过type类的构造方法创建。
那么,创建类就可以有两种方式:
a). 普通方式
class Foo(object):
def func(self):
print 'hello wupeiqi'
b).特殊方式(type类的构造函数)
def func(self):
print 'hello wupeiqi'
Foo = type('Foo',(object,), {'func': func})
#type第一个参数:类名
#type第二个参数:当前类的基类
#type第三个参数:类的成员
==》 类 是由 type 类实例化产生
那么问题来了,类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性 metaclass,其用来表示该类由 谁 来实例化创建,所以,我们可以为 metaclass 设置一个type类的派生类,从而查看 类 创建的过程。

class MyType(type):
def __init__(self, what, bases=None, dict=None):
super(MyType, self).__init__(what, bases, dict)
def __call__(self, *args, **kwargs):
obj = super().__call__(*args, **kwargs)
# 调用实例的 __init__ 方法
if hasattr(obj, '__init__'): # 确保实例有 __init__ 方法
obj.__init__(*args, **kwargs)
return obj
class Foo(metaclass=MyType): # 注意 Python 3 的语法
def __init__(self, name=None): # 添加了默认参数
self.name = name
# 现在可以正确创建 Foo 的实例了
obj = Foo() # 使用默认参数
obj_with_name = Foo("John") # 使用提供的参数
print(obj.name) # 输出:None
print(obj_with_name.name) # 输出:John


